How to Add Memory to an AI Agent
Introduction
Most teams try to add memory to an AI agent the same way they add caching: flip on a feature, point it at a store, and hope the agent magically becomes more helpful next week than it was five minutes ago. That usually works for one demo, then falls apart as soon as the agent starts replaying stale facts, old tool output, or half-relevant conversation fragments.
If you want to know how to add memory to an AI agent in 2026, the useful answer is not “install a memory library.” The useful answer is to add memory in layers: keep the current thread alive first, promote only durable facts second, and then make retrieval smart enough to load the right memories instead of all of them.
Think of memory less like a voice recorder and more like a field notebook. A recorder captures everything and makes later review painful. A good notebook keeps the details that will still matter after the meeting ends.
This guide walks through the smallest production-friendly path: session memory, durable memory, typed retrieval, and the point where semantic or graph memory actually becomes worth the operational cost.
What “adding memory” to an AI agent actually means
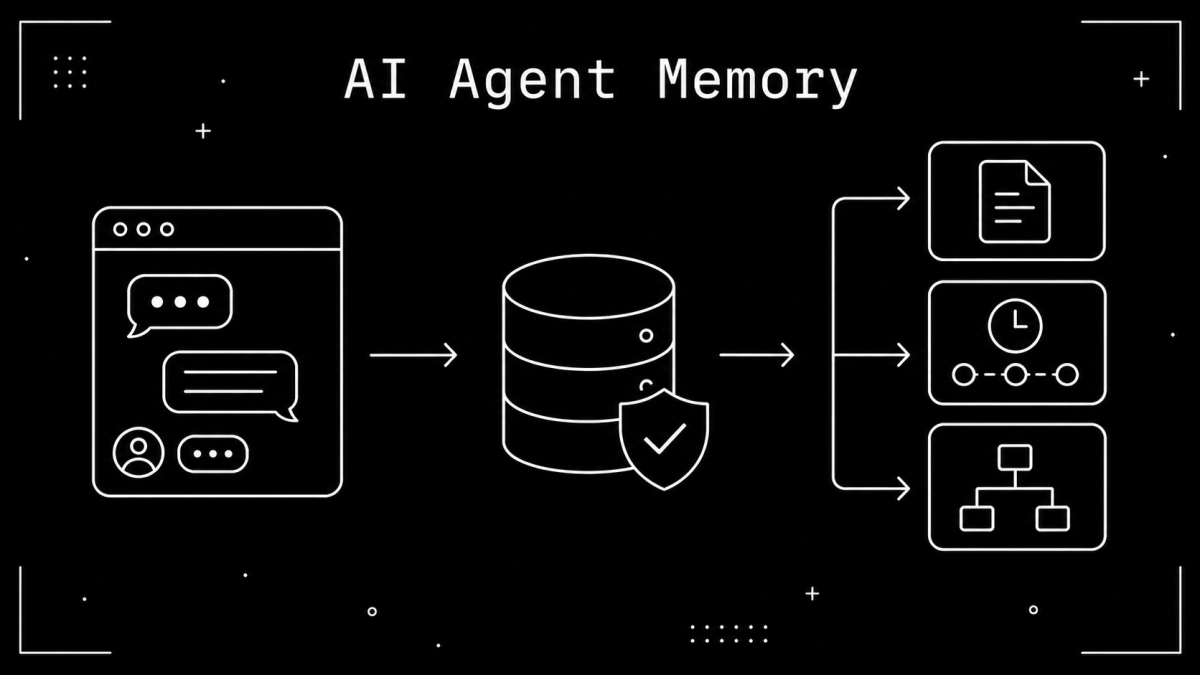
Before writing code, it helps to separate three things that often get collapsed into one vague “memory” bucket.
Session memory keeps the current conversation alive.
Durable memory stores facts or outcomes that should survive future runs.
Retrieval decides which stored memories deserve to re-enter the prompt.
That split matters because these layers solve different problems. The OpenAI Agents SDK agent memory docs explicitly separate distilled memory from conversational session memory. The OpenAI memory reference also makes a practical point many people miss: a SQLite session defaults to :memory:, which disappears when the process ends, so persistence only happens when you provide a real file path.
LangGraph documents the same distinction from another angle. Its add-memory guide treats short-term memory as thread-level persistence and long-term memory as user- or application-level data stored across conversations. That is a much better mental model than “one giant memory store.”
So when someone says “add memory,” the first engineering question should be: what exactly do you want the agent to remember next time? That answer determines the first layer you should add.
Step 1: add session memory so the current thread survives
The first upgrade is usually not long-term memory. It is continuity.
If your agent loses track of the current conversation after a tool call, worker restart, or second turn, long-term memory will not save you. You need a session layer or checkpointer first so the current thread can continue coherently.
LangGraph’s documentation shows the minimal version clearly:
# Thread-level memory keeps the current conversation alive
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph
checkpointer = InMemorySaver()
builder = StateGraph(...)
graph = builder.compile(checkpointer=checkpointer)
That gives you multi-turn continuity at the thread level. In production, the same guide recommends a database-backed checkpointer such as PostgresSaver, which is the right move once you need restarts and multiple workers to behave consistently.
If you are in the OpenAI Agents SDK instead, the same principle applies even though the vocabulary is different. A reusable session ID and a persistent session backend give you conversation continuity; a file-backed SQLite session persists, while an in-memory session does not.
This is the point where many teams stop and assume they added memory. In reality, they added recall for the current thread. That is valuable, but it is only the first shelf in the workshop, not the whole storage system. The next step is deciding what should still be true after the thread is gone.
How to add memory to an AI agent across runs with a durable store
Once the current thread is stable, the next layer is durable memory across runs. This is where you stop replaying everything and start storing only what deserves to survive.
The LangChain long-term memory docs show the cleanest baseline: give the agent a store and let tools read from or write to that store using a stable identity such as user_id. That is enough to remember a preference, a customer detail, or an active workflow across sessions without turning the whole transcript into memory.
The data model can stay simple at first:
-- Durable memory should be scoped, typed, and easy to invalidate
CREATE TABLE agent_memory (
id TEXT PRIMARY KEY,
owner_id TEXT NOT NULL,
scope TEXT NOT NULL,
memory_type TEXT NOT NULL,
value_json TEXT NOT NULL,
source TEXT,
last_verified_at TIMESTAMP,
expires_at TIMESTAMP,
superseded_by TEXT
);
That schema handles more than it looks like. owner_id stops cross-user leakage. scope separates user, project, or workspace memory. memory_type gives you a hook for different retrieval behavior. expires_at and superseded_by are what keep old facts from haunting later prompts.
The operational rule is simple: durable memory should store stable outcomes, not full reasoning trails. Good candidates include user preferences, standing constraints, named entities, active project summaries, and confirmed task state. Bad candidates include verbose tool logs, speculative chains of thought, and every transient message the model happened to produce.
If you want the longer architecture view after this tutorial, how to persist ai agent memory across sessions is the natural companion. But before you add more infrastructure, you need to tighten what counts as a memory at all.
Step 3: separate fact, event, and workflow memory so retrieval matches the job
Not all memory behaves the same way, and production systems get better the moment you stop pretending it does.
Redis’s current memory architecture guide is useful here because it breaks memory into distinct categories. Episodic memory captures experiences and sequences of events. Semantic memory captures factual knowledge. Procedural memory captures how to do something. Community discussions around LangChain keep circling the same point: developers want these separated because each one should be written, searched, and expired differently.
A practical version looks like this:
Fact memory: user preferences, profiles, durable business facts, environment details.
Event memory: what happened in a specific task, ticket, or workflow, with timestamps.
Workflow memory: reusable procedures, playbooks, and stable instructions.
Your write path can reflect that split without getting fancy:
# Promote only memories that have a stable job to do later
def classify_memory(candidate: dict) -> tuple[str, str] | None:
if candidate["kind"] == "preference":
return ("facts", candidate["key"])
if candidate["kind"] == "task_outcome":
return ("events", candidate["task_id"])
if candidate["kind"] == "procedure":
return ("workflows", candidate["name"])
return None
This matters because retrieval should match the memory’s job. Fact memory can often be pulled with direct keys or metadata filters. Event memory usually needs time and scope filters. Workflow memory often works best as a curated set of instructions rather than free-text recall. If you use one retrieval method for all three, you usually end up with noisy prompts and fragile answers.
In practice, typed memory is what turns “the agent remembers things” into “the agent remembers the right category of thing for the current job.” That sets up the real scale decision: when simple filters stop being enough.
When to add semantic search, Redis, or graph memory instead of staying simple
This is where a lot of architectures become expensive too early.
LangGraph’s docs show a clear escalation path. You can start with a plain store, then enable semantic search later by adding embeddings to the store index. That is a good default because it forces you to prove your memory contract before you introduce fuzzy retrieval.
Stay with a simple SQL or metadata-filtered store when:
You mostly fetch memory by user, workspace, project, or ticket.
Your durable items are structured facts or short summaries.
You still need to debug why the agent remembered something.
Add semantic search when:
Users refer to older facts in many different phrasings.
You need recall by similarity instead of exact scope and key.
The memory set has become too large for direct filtering alone.
Consider Redis or a dedicated memory backend when:
You need a low-latency store plus checkpointing across multiple workers.
Memory writes and reads now happen at high frequency.
You need semantic search and operational durability in one place.
Consider graph memory only when relationships are the actual retrieval problem. If the task depends on connections between entities, dependencies, and timelines, graph structure can help. If the task is just “remember the user’s timezone and their preferred deployment target,” graph memory is probably a costly detour.
That is why the cleanest pattern is often boring at first: start with scope filters, typed memory, and a durable store, then add semantic retrieval only after your real query patterns justify it. The moment you know when to reach for those heavier tools, you also know what can still stay simple.
Common implementation mistakes: stale facts, memory poisoning, and transcript bloat
The first common mistake is storing too much. When every user utterance, tool log, and model output gets promoted into memory, retrieval becomes a landfill search problem. The agent is not more informed; it is just carrying more junk.
The second mistake is storing facts without freshness rules. Preferences change. Project state changes. Tool outputs get invalidated. If durable memories never expire or get superseded, the agent starts sounding confident about things that stopped being true two weeks ago.
The third mistake is writing memory before it is verified. Hacker News discussions around persistent agent memory keep surfacing the same risk: naive write-through systems can poison memory with temporary assumptions, wrong extracted facts, or user-introduced noise. A memory that is easy to write but hard to revoke will eventually bite you.
The fourth mistake is confusing session history with useful memory. OpenAI’s docs explicitly separate distilled memory from conversational history for a reason. Memory should compress future work, not replay the past in full.
A good review checklist is short:
Does this memory help a future run make a better decision?
Is it scoped to the right user, project, or workflow?
Can it expire, be replaced, or be corrected cleanly?
Would a direct source lookup be better than storing it?
If a memory fails those checks, it probably does not belong in the prompt path. Once you get disciplined about those failure modes, the final piece becomes much easier to manage: how to grow the system without rebuilding it every month.
Start small, then let memory earn complexity
If you are figuring out how to add memory to an AI agent, start with three upgrades and stop there until the system proves it needs more.
First, add session continuity so the current thread survives. Second, add a tiny durable store for stable facts and outcomes. Third, add retrieval rules that pull back only the memories relevant to the next turn.
That sequence is enough for a surprising number of production agents. It is also easier to debug, cheaper to run, and much safer than jumping straight to “AI memory platform” thinking on day one.
The real goal is not to make your agent remember everything. It is to make it remember the few things that still matter when the next run starts. If you build with that restraint, memory stops feeling like magic and starts feeling like good software design.